TITAN: A Next-Generation Infrastructure for Integrating Computing and Communication
Grant Number: CDA-9401156
Computer Science Division
University of California, Berkeley
Technical Progress Report (8/1/95 -7/31/96)
Overview
The Computer Science faculty at the University of California at
Berkeley is developing as its computing and communication
infrastructure a new type of computing system, called Titan. This
computing system comprises an integrated ensemble of computing and
communication elements, organized to provide the user with a number of
services that we think will characterize the practice of computing in
science and engineering into the next century, and designed around the
view that the building which contains the research enterprise defines
a natural physical, administrative, and organizational structure for
the system as a whole. We envision this system as comprising a core
of computing resources, including huge processing power, memory
storage, file storage, and tertiary storage, accessible through
innovative parallel languages, libraries, and tools and connected to a
shell of multimedia capabilities, including continuous media
transmission to the desktop and wireless communication throughout the
building. In addition, there is a mantle of powerful graphics
capabilities that is intimately connected to the core, but more
similar in function to the media shell. The system serves as
infrastructure for several large applications efforts, which in turn
serve to drive the system design. The unique thrust of the project is
that rather than constructing the system out of an ensemble of
specialized components, e.g., massively parallel processors, file
servers, rendering engines, etc., we are constructing it out of
collections of the general-purpose, cost-effective, high-performance
building block that is typified by the desktop computer. We are
developing the communications infrastructure, operating system
support, programming environment, and tools that will enable
construction of large scale systems out of complete commodity
computers. In this report we outline the progress on Titan during
its second year.
- Section [equipment]
describes the equipment that has been tested and deployed this
year.
- Section [core systems] describes progress on the core architecture and operating
systems component.
- Section [core software] describes progress on the core
compilation, programming language and tools.
- Section [shell] describes the shell multimedia component.
- Section [drivers] the driving applications.
Physical Infrastructure
Networking Infrastructure
We demonstrated the ability to quickly extend the production
networking infrastructure of the department with dedicated, "logical
networks" to meet the
emerging needs of new research projects. This demonstration included
a special network for
internet services, used currently by the Inktomi
Scalable Web Search Engine , and a wireless network, used by
the Daedalus project, described below.
Using network management software and the analysis capbilities embedded
in the network "hubs" purchased by Titan last year, we have been able to evaluate the
emerging demands of multimedia traffic across the department and its impact
on traditional shared-media networks, such as ethernet and FDDI.
Based on this analysis, it was clear that we needed to provide a scalable,
switched network infrastructure throughout the department, incorporating the
benefits of traffic isolation between communicating peers and high bandwidth
paths to networks outside the department. The introduction of switching
equipment allows us to greatly extend the traffic carrying capacity of our
existing wiring infrastructure, responding to new network
requirements without the installation of new fiber or cable. Finally,
switched networks are required to provide a large aggregate bandwidth to
the core computing resources.
The key challenge in implementing switch-based networks is to provide
the facilities which are present in a shared media network (and
assumed by the client machines), while obtaining the scalability of
the switched network. Facilties required to provide virtual LAN
emulation include connection management, multicast and broadcast
services. We have demonstrated and deployed a sizable switched network
in support of the NOW cluster (described below).
We will shortly
expand this switched network to encompass desktop machines located throughout the
department, providing Virtual networking, the capability to provide an arbitrary
network IP segment to any given client by software modification of the network
equipment, no wiring changes are necessary. This capability is driven by the need
of collaborating groups to be able to participate in multimedia collaborations
without impacting other network users.
Core Computing and Network Hardware
We have completed construction of our first prototype core computing cluster,
described below.
Multimedia Equipment
We have completed construction of our multimedia authoring capability
and support for multimedia presentation.
Support Infrastructure
We have expanded the storage capacity of the research file server,
purchased on the Mammoth IIG grant, and allowed individual research
groups to further expand the capacity of this shared resource. The
Software WareHouse staff and continued to expand the applications
and platforms supported by the
SWW.
Core: Architecture and Operating Systems (T. Anderson, D. Culler, D. Patterson)
This component seeks to provide software and hardware support for
using a network of workstations (NOW) as a distributed supercomputer
on a building-wide scale. This draws upon the dramatic technological
convergence among local-area networks, telecommunications, and
massively parallel processors, which is yielding fast, cost-effective,
switch-based networks, such as ATM and Myrinet. The advance in
communication makes it possible to closely integrate processors,
memory, and disks across the network. Furthermore, individual
workstations have become almost as powerful as traditional
supercomputers, making them attractive to hook together into a
high-performance integrated system.
We are conducting research and development into network interface
hardware, communications protocol software, network-wide resource
management, distributed scheduling, and parallel file systems. Our
approach is to leverage as much as possible from commercially
available systems for fast prototyping and to track the dramatic
growth in the technology. The target is a 100 processor system that is
(i) high performance (delivering a large portion of the NOW to
demanding sequential and parallel applications while guaranteeing good
performance to interactive users), (ii) incrementally scalable (system
capacity can increase simply by buying more workstations), (iii) fault
tolerant (the system continues to be usable even when a single CPU
fails), and (iv) easy to administer. One way to view the project is to
re-think distributed systems, assuming a low overhead switched
communication fabric. This impacts all aspects of the operating
system: the file system, virtual memory, resource scheduling, etc.
This portion of the research is funded in part by ARPA, through the NOW project.
We have completed construction of the first prototype NOW-1 cluster,
shown below, which consists of 32 SparcStation 10s and 20s (on the left), donated by
Sun Microcomputer Corporation, integrated by a Myrinet high performance network
(shown in the upper right-hand portion of the figure). Some of the individual
nodes have additional external disks for file system research. This cluster
is now being used both within the NOW project for system research and by general
members of the department as a core computing platform. We developed an
extensive testing capability for this first generation of the Myrinet hardware.
With our fast communication layer, we were able to reveal significant problems
with this prototype hardware under heavy load. We have now received and tested
the follow-on generation of the Myrinet switches and network adapter cards.
These have proved quite solid and we are in the process of converting the
initial NOW-1 cluster to the new myrinet hardware, as well as using it
throughout the NOW-2 cluster.

The NOW-1 cluster.
32 Sun SPARCstation 10's and 20's.
|
We have acquired two-thirds of 100 UltraSparc NOW-2 cluster, shown in
part below, and have begun constructing the high performance and
mezzanine networks. This represents a shift in our original plan
to build the core computing cluster out of HP platforms.
We have also acquired a small cluster eight HP J200s.

The NOW-2 cluster.
60 UltraSPARC's -- still under construction.
|
Fast Communication
Previous work in fast communication has focused on exploiting the
characteristics of specific hardware platforms. We have completed
our first major step in demonstrating a generic communication API
that achieves high performance on a wide range of platforms.
The Generic Active Message[GAM 1.0] has been completed and is used by
several research groups across the country. This has allowed us to
perform a detailed implementation study to access the performance
trade-offs across rich architectural design space, ranging from clusters
to MPPs. We have completed a GAM
implementation study, with implementations on Myrinet, Intel Paragon,
and Meiko CS-2 released to the research community via the Web
(http://now.cs.berkeley.edu/AM/lam_release.html). We have completed an
automated microbenchmark suite as a calibration tool for the
hardware/software combination that supports any GAM layer[Cul*96],
based on the LogP model.
LogP[Cul*93] was developed as realistic model for parallel algorithm design, in which critical performance issues could be addressed without reliance on a myriad of idiosyncratic machine details. The performance of a system is characterized in terms of four parameters, three describing the time to perform an individual point-to-point message event and the last describing the crude computing capability, as follows.
- Latency: an upper bound on the time to transmit a message from its source to destination.
- overhead: the time period during which the processor is engaged in sending or receiving a message
- gap: the minimum time interval between consecutive message transmissions or consecutive message receptions at a processor, and
- Processors: a crude metric of computing power.
The total time for a message to get from the source
processor to the destination is o+L+o. It is useful to distinguish the two
components, because the overhead reflects the time that the main
processor is busy as part of the communication event, whereas the
latency reflects the time during which the processor is able to do
other useful work. The gap indicates the time that the slowest stage,
the bottleneck, in the communication pipeline is occupied with the
message. The reciprocal of the gap gives the effective bandwidth in
messages per unit time.
By executing a simple microbenchmark for a range of message burst
lengths and compute intervals between messages, we construct a
signature consisting of several message issue curves, each
corresponding to a different value of D.
From this signature we can extract the LogP parameters. A summary of the
results for our NOW-1 cluster and two MPP,
along with two variations that illustrate how sensitive the
technique is to hardware characteristics. The bars on the left show the
one-way time divided into overhead and latency, while the ones on the
right show the gap. The Myrinet time is roughly 50% larger than the
two MPP platforms, although the message bandwidth is comparable. The
larger overhead on the Myrinet (4.6 usec) compared to the MPP
platforms (3.3 usec and 3.7 usec) reflects the first of the dimensions
of the communication architecture design space. The Meiko and Paragon
NIs connect to the cache-coherent memory bus, so the processor need
only store the message into the cache before continuing. On the
Myrinet platform the NI is on the I/O bus, and the processor must move
the message into the NI with uncached stores, resulting in larger
overhead.
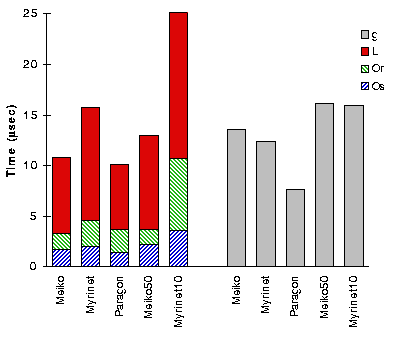
The latency and gap reflect a key design issue: the
processing power of the NI. The Paragon has the lowest latency, 6.3
usec, followed by the Meiko and Myrinet, with latencies of 7.5 and
11.1 usec, respectively. This indicates the advantage of the
microprocessor used in the Paragon over the custom embedded processors
in the Meiko and Myrinet designs. The Paragon also has the lowest gap,
7.6 usec, compared to 12.4 usec for the Myrinet 13.6 usec for the
Meiko. The difference between the Meiko and Myrinet is
interesting. Even though the Meiko communication processor resides on
the memory bus, it has no caches and so must load messages using
uncached reads from the main processor cache, affecting the rate
at which it can send messages. On the Myrinet, the main processor has
already deposited the messages into NI memory, where the communication
processor can access it quickly. Furthermore, since a substantial part
of the latency is the processing in the NI, rather than the actual
network transfer, trade-offs exist between the overhead and latency
components. For example, the Myrinet latency can be reduced with an
increase in overhead by performing the routing lookups on the main
processor. While this change might reduce the overall communication
cost, since the main processor is faster, bus transfers and other
factors might mitigate the advantage. The microbenchmark provides a
means of quantifying such trade-offs.
The microbenchmark is a valuable tool for evaluating design changes in
the communication hardware and software. In many cases, the
performance impact is unexpected and subtle, as illustrated by two
slightly older variants on our main platforms. One expects the
overhead to track the processor speed, but L and g to be
unaffected. When we run the microbenchmark on an older Meiko with 50
Mhz SuperSparc processors using the same Active Message
implementation, the o's increase slightly while L and g increase by
about 30%, as illustrated by the Meiko50 bars. Part of
the reason is that this machine has a slower memory bus (40 vs. 45
MHz), and the NI processor runs at the memory bus speed.
One generally expects program performance to improve with the addition
of a large second level cache, however, this may not be the case for
communication. The Myrinet10 bars summarize the
performance of an alternative Myrinet platform using SparcStation 10s
with the same 50MHz SuperSPARC, and a second-level cache. We see a
dramatic increase in overhead, os =3.6 usec and or = 4.0 usec!
Processor loads and stores the NI incur an extra delay through the
second-level cache controller before reaching the I/O bus. We believe
the I/O bus is slower, as well, accounting for the increase in g,
since the NI processor is clocked at the I/O bus speed. The
Microbenchmark tool also provides evaluation under load and a
calibration of bulk transfer performance, including the bandwidth
obtained as a function of transfer size and a breakdown of the
overhead component of the transfer time[Cul*96].
Based on the combination of implementation and application studies, we
have iterated the design of the communication API and produced a much
complete abstraction, which supports multiprogramming and is more
deeply integrated with threads. It has a well-defined error model and
supports development of fault-tolerant applications. It also supports
client-server kinds of communication, where either the client or the
server may itself be a parallel application. This specification is
available on the web
(http://now.cs.berkeley.edu/AM/active_messages.html). We have
developed a portable reference implementation UDP and verified its
utility against our spectrum of applications. We are currently
implementing this new layer on the new generation of Myrinet
hardware. When complete, this will not only allow fast communication
among many processes (and many threads) on each of the node
simultaneously, but will tolerate interruptions in service and
automatically reconfigure the networks. It should be possible to
completely rewire the NOW while parallel programs are running. This
work has generated a broad range of requirements for various naming,
configuration, registration, and administration services.
- [Cul*96] D. Culler, L.T. Liu, R. P. Martin, C. O. Yoshikawa, "Assessing Fast Network Interfaces" IEEE Micro (Special Issues on Hot Interconnects) vol 16, no. 1, Feb 1996
- [Arp*95] R. Arpaci, D. E. Culler, A. Krishnamurthy, S. Steinberg, and K. Yelick, "Empirical Evaluation of the CRAY-T3D: A Compiler Perspective", Proceedings of the 22nd Annual International Symposium on Computer Architecture, June 1995.
- [LiCu95] Lok Tin Liu, David E. Culler, "Evaluation of the Intel Paragon on Active Message Communication"
, Intel Supercomputer Users Group Conference, June 1995.
GLUnix: Global Operating Systems Layer
We have made substantial progress toward building Global Operating
Systems layer for a NOW,
including simulation studies of key design issues in building an
operating system for a NOW [Dah*94, Arp*95, Dus*96] and working
prototypes of both the serverless network file system [And*96] and the
global operating system itself, GLUnix.
In the area of global resource allocation, we have conducted a
simulation study to examine the impact of sharing a NOW between
interactive and parallel jobs [Arp*95]. Through simulations, our study
examined many of the issues that arise when combining these two
workloads. Starting from a dedicated NOW just for parallel programs,
we incrementally relaxed the restrictions until we have a
multiprogrammed, multiuser NOW for both interactive sequential users
and parallel programs. We showed that a number of issues associated
with the distributed NOW environment (e.g., daemon activity) have
little effect on parallel program performance. However, efficient
migration to idle workstations is necessary to maintain acceptable
parallel application performance. We showed that an optimal time to
wait before recruiting an idle machine for use by parallel programs
exists; for the research cluster we measured, this recruitment
threshold was just 3 minutes. Finally, we quantified the effects of
the additional parallel load upon interactive users by keeping track
of the potential number of user delays in our simulations. We showed
that when we limit the maximum number of delays per user, we can still
maintain acceptable parallel program performance. In summary, we
found that 2:1 rule applies: a NOW cluster of approximately 64
machines can easily sustain a 32-node parallel workload in addition to
the sequential load placed upon it by interactive users.
In followup
work, we devised a scalable, distributed algorithm for time-sharing
parallel workloads as an alternative to centralized coscheduling
[Dus*96]. Implicit scheduling allows each local scheduler in the
system to make independent decisions that dynamically coordinate the
scheduling of cooperating processes across processors. Of particular
importance is the blocking algorithm which decides the action of a
process waiting for a communication or synchronization event to
complete. Through simulation of bulk-synchronous parallel
applications, we find that a simple two-phase fixed-spin blocking
algorithm performs well; a two-phase adaptive algorithm that gathers
run-time data on barrier wait-times performs slightly better. Our
results hold for a range of machine parameters and parallel program
characteristics. These findings are in direct contrast to the
literature that states explicit coscheduling is necessary for
fine-grained programs. We show that the choice of the local scheduler
is crucial, with a priority-based scheduler performing two to three
times better than a round-robin scheduler. Overall, we find that the
performance of implicit scheduling is near that of coscheduling (+/-
35%), without the requirement of explicit, global coordination.
We have constructed a working prototype of GLUnix, providing a single
system image for running sequential and parallel programs across a
NOW. GLUnix co-schedules parallel jobs, detects idle resources,
migrates processes away from interactive use, predictively prepages
the working set of a machine back in advance of the user returning to
their machine, transparently forwards I/O from migrated processes, and
integrates process management for parallel and sequential jobs (for
example, control-C kills all of the processes involved in running a
parallel job). This software is currently in day-to-day use by a
graduate level parallel programming course at Berkeley as well as by
over 20 Berkeley graduate students. Over the next year, we plan to
(i) build a system for secure interposition agents, allowing
full-fledged operating system extensions to be inserted transparently,
securely, and portably at the system call level, with as high
performance as if these extensions were integrated into the OS kernel.
Example applications include GLUnix and xFS. We plan to (ii) build a
Web interface onto a NOW allowing anyone with Web access to securely
run applications on our NOW cluster, with secure, coherent, cached
file access to remote files over the Web -- effectively, turning the
Web into a computer and your browser into your desktop. The mechanism
for enforcing security is the interposition agents work described
above. And finally, we plan to (iii) open the NOW cluster to a wide
number of users, collect traces of their workloads, and use those
traces to drive development of algorithms for NOW resource management.
Finally, we have built a working user-level prototype version of
network RAM (virtual memory paging over the network). This effort led
us to measure the virtual memory performance on a number of platforms,
including OSF, Solaris, SunOS, HPUX, and AIX; these measurements
showed that the overhead of just taking a page fault (without going to
disk) on these systems will more than double the cost of fetching a
remote page over a fast network with well-designed communication
protocols. As a result, we are in the initial stages of studying what
optimizations we have to apply to these virtual memory systems to
provide faster page fault handling. We are also exploring software
fault isolation techniques [Wah*93] to implement network RAM entirely
in software, using object code re-writing techniques to avoid the
overhead of taking page faults.
xFS: Serverless Network File Service
In the area of file systems, we have conducted a simulation study to
demonstrate the value of using remote client memory to improve file
caching performance [Dah*94]. Emerging high-speed networks will allow
machines to access remote data nearly as quickly as they can access
local data. This trend motivates the use of cooperative caching:
coordinating the file caches of many machines distributed on a LAN to
form a more effective overall file cache. We examined four cooperative
caching algorithms using a trace-driven simulation study. Based on
these simulations we conclude that cooperative caching can
significantly reduce response time for file system reads and that
relatively simple cooperative caching algorithms are sufficient to
realize most of the potential performance gain.
Extending the cooperative caching work, we have proposed and
implemented a new paradigm for network file system design, serverless
network file systems; a paper on this was an award paper at SOSP, the
premier research conference in operating systems [And*96]. While
traditional network file systems rely on a central server machine, a
serverless system utilizes workstations cooperating as peers to
provide all file system services. Any machine in the system can
store, cache, or control any block of data. Our approach uses this
location independence, in combination with fast local area networks,
to provide better performance and scalability than traditional file
systems. Further, since any machine in the system can assume the
responsibilities of a failed component, our serverless design also
provides high availability via redundant data storage. To demonstrate
our approach, we have implemented a prototype serverless network file
system called xFS. Preliminary performance measurements suggest that
our architecture achieves its goal of scalability. For instance, in a
32-node xFS system with 32 active clients, each client receives nearly
as much read or write throughput as it would see if it were the only
active client. Even though the prototype is untuned, measurements of
the industry-standard Andrew benchmark on 32 nodes showed a factor of
two improvement in performance relative to NFS and AFS. Over the next
year, we plan to (i) deploy xFS into production use, and (ii)
investigate how to make xFS self-managing, so that it automatically
reconfigures itself in response to changes in the underlying hardware
or application workload to provide robust high performance across a
spectrum of operating environments.
- [And*95] T. Anderson, D. Culler, D. Patterson, and the NOW team, "A Case for NOW (Networks of Workstations)," IEEE Micro, Feb. 1995.
- [Arp*95] R. Arapaci, A. Dusseau, A. Vahdat, T. Anderson, and
D. Patterson, "The Interaction of Parallel and Sequential Workloads on
a Network of Workstations." Proc. 1995 ACM SIGMETRICS Conference on
the Measurement and Modelling of Computer Systems , May 1995.
- [And*96]T. Anderson, M. Dahlin, J. Neefe, D. Patterson,
D. Roselli, R. Wang. "Serverless Network File Systems." To appear,
ACM Transactions on Computer Systems, Feb. 1996. Also appeared as an
award paper in Proc. Fifteenth Symposium on Operating Systems
Principles , Dec. 1995."
- [Arp*95] R. Arpaci, A. Dusseau, A. Vahdat, T. Anderson and
D. Patterson. "The Interaction of Sequential and Parallel
Workloads on a Network of Workstations." Proc. of the ACM
SIGMETRICS Conference on the Measurement and Modelling of Computer
Systems , May 1995.
- [Dah*94] M. Dahlin, R. Wang, T. Anderson, and D. Patterson,
"Cooperative Caching: Using Remote Client Memory to Improve File
System Performance," Proc. of the First USENIX Symposium on
Operating Systems Design and Implementation, pp. 267-280, Nov. 1994.
- [Dus*96] A. Dusseau, R. Arpaci, and D. Culler, �Effective
Distributed Scheduling of Parallel Workloads,� To appear,
Proc. 1996 SIGMETRICS Conference, May 1996.
Network Security (E. Brewer)
One of the difficult challenges in implementing a large-scale network
infrastructure is the need to overcome the myriad of severe security
flaws in current network software, including all protocols based on
UDP/IP and TCP/IP. For example, it is relatively easy to watch
ethernet traffic for passwords, or worse, to falsify packets in order
to gain illegal access to a machine. For example, it is possible to
spoof NFS with false packets into providing write access to files that
a given user should not be able to change.
It is possible to eliminate these problems by fixing all of the common
network software, including NFS, rlogin and the e-mail system. However,
these programs are numerous and very complex, thus prohibiting any
realistic chance of fixing all such flaws.
Instead, we are building a network security monitor called IPSE
(Internet Protocol Scanning Engine) . IPSE will be deployed
on each of the Titan subnets to monitor traffic for in-progress
security attacks. In particular, IPSE performs three jobs:
- Prevent false-packet (spoofing) attacks for TCP-based protocols.
In particular, IPSE can detect falsified TCP packets and kill that connection, thus preventing the completion of the attack.
- Detect UDP-based spoofing attacks. Although we can not prevent
UDP attacks, we can detect them and notify the system administrator of an
attack in progress.
- Detect clear-text passwords. Although we can not prevent passive attacks (those that just listen on a network), we can look for the same things that they do -- clear-text passwords in particular. This information allows
system administrators to eliminate these flaws by educating users to avoid
these mistake through the use of Kerberos and other software that avoids
clear-text passwords.
IPSE is easy to extend on a per-protocol basis, so that the filtering
can be easily improved as new security holes are discovered. By taking
this approach, we have a manageable solution that sits beside existing
network software (with its security flaws). Although we can not
prevent every attack, we can prevent several kinds and detect most
of the others in-progess, which may allow the system administrator
to either prevent completion or discover the identity of the attacker.
Core: Compiler, Library, and Language Component
In this component of Titan we seek to develop the programming support
required to make the core computing resources available to
application, building on our language, compiler, and library work for
large-scale parallel machines. This work is now focused on
the NOW prototypes described above and on recent parallel machines,
such as the Cray T3D. This portion of the research is funded in
part by DOE through the Castle Project.
Multipol (K. Yelick)
Multipol is a library of distributed data structures designed to
handle distributed memory multiprocessors and workstation networks. It
currently contains the following data structures: an event graph for
conservative or speculative event-driven simulation, which is used in
a parallel timing level circuit simulator, a task queue for dynamic
load balancing, which is used in four search-like applications, a hash
table, which is used in a game search problem, a tree, which is used
in a phylogeny tree application from biology an oct-tree, which is
used in an n-body calculation, and a linked list, which is used in a
cell simulation algorithm. Multipol uses split-phase operations and
lightweight multi-threading to mask communication latencies and remote
computations delays.
The multipol library has been publically released
(http://HTTP.CS.Berkeley.EDU/projects/parallel/castle/multipol/).
Several new publications have appeared
-
``Multipol: A Distributed Data Structure Library,''
S. Chakrabarti, E. Deprit, J. Jones, A. Krishnamurthy, E.-J. Im, C.-P. Wen, and K. Yelick,
- UCB//CSD-95-879, July 1995;
``Portable Runtime Support for Asynchronous Simulation,''
C.-P. Wen and K. Yelick, International Conference on Parallel Processing, August 1995;
- ``Portable Parallel Irregular Applications'',
by K. Yelick, S. Chakrabarti, E. Deprit, J. Jones, A. Krishnamurthy, and C.-P. Wen,
Workshop on Parallel Symbolic Languages and Systems, Oct 1995,
To appear in Lecture Notes in Computer Science.
Split-C (D. Culler, K. Yelick)
A new version of Split-C
using GAM has been completed, as have two
versions using the more powerful AM 2.0 layer (currently on the
reference implementation). One of these makes extensive use the
the integration with POSIX compliant threads in the new AM layer.
A new version of Split-C using the message coprocessors on the Paragon is
available.
Split-C has also been ported to the Cray T3D[Arp*95].
A detailed performance comparison of most of these Split-C implementations
has been submitted for publication.
The Mantis parallel debugger has been ported to NOW, and a paper
``The Mantis Parallel Debugger,''
by S. Lumetta, and D. Culler, is to
appear in the Proceedings of the First Symposium on Parallel and
Distributed Tools, Philadelphia, PA, May 1996.
Multithreading is an important parallel programming paradigm that is widely
popular, and recently added to Split-C. In addition to the above work based
on AM2, S. Goldstein has explored multithreading in his thesis work
This work has
introduced the notion of lazy threads, which are not instantiated until
needed. These threads are implemented by the compiler in contrast to the
Solaris threads used in the AM2 multithreaded Split-C. This work is aiming
to produce a Split-C++ implementation, combining Split-C and C++.
Publications are available at http://www.CS.Berkeley.EDU/~sethg/papers.html.
-
[Arp*95] ``Empirical Evaluation of the CRAY-T3D: A Compiler Perspective'', by
R. Arpaci, D. Culler, A. Krishnamurthy, S. Steinberg, and K. Yelick,
International Symposium on Computer Architecture, June 1995.
Titanium (A. Aiken, S. Graham, K. Yelick)
Titanium is a project to build an optimizing compiler for explicitly
parallel languages like Split-C. The optimizations include minimizing
communication and synchronization costs. The current prototype
handles a ``pointer-free'' subset of Split-C; it automatically does
message pipelining, and analyzes synchronization and shared memory accesses
to introduce automatic overlap of read/write operations. Speedups of
20\% to 30\% on kernels like the FFT have been obtained. See
``Optimizing Parallel Programs with Explicit Synchronization,''
A. Krishnamurthy and K. Yelick, Programming Language Design and Implementation,
June 1995.
Communication Optimizations in Data Parallel Programs (K. Yelick)
Reducing communication cost is crucial to achieving good performance
on scalable parallel machines. Working with the HPF compiler group at
IBM T.J. Watson, one of our students, Soumen Chakrabarti, has
developed a new compiler algorithm for global analysis and
optimization of communication in data-parallel programs. The
algorithm is distinct from existing approaches in that rather than
handling loop-nests and array references one by one, it considers all
communication in a procedure and their interactions under different
placements before making a final decision on the placement of any
communication. It exploits the flexibility resulting from this
advanced analysis to eliminate redundancy, reduce the number of
messages, and reduce contention for cache and communication buffers,
all in a unified framework. In contrast, single loop-nest analysis
often retains redundant communication, and more aggressive dataflow
analysis on array sections can generate too many messages or cache and
buffer contention. The algorithm has been implemented in the IBM pHPF
compiler for High Performance Fortran. During compilation, the number
of messages per processor goes down by as much as a factor of nine for
some HPF programs. Performance was measured on the IBM SP2 and the
Berkeley NOW platform, a network of Sparc workstations connected by a
Myrinet switch. On the SP2 and the NOW, communication time is reduced
by a factor of 2 to 3, which in the applications we studied, resulted
in an overall performance gain of 10-30% on the SP2 and 20-40% on the
NOW. This is work is described in a forthcoming PLDI '96 paper:
.Global
Communication Analysis and Optimization, by Soumen
Chakrabarti, Manish Gupta and Jong-Deok Choi.
pSather (J. Feldman)
Significant progress was made on the serial Sather compiler and
class library. Sather is a programming language with
significant and growing use in the computational community. The
Sather home page
provides
a complete introduction including the text of an invited article
appeared in the September 1995 issue of Computers in Physics. We
completely redesigned the compiler using new principles promoted
by the 1.0 version of the language. The Sather 1.0 system was
made available for distribution in the summer of 1994 and has
already developed a world-wide user community. Current work is
directed towards inter-operability and programming in the large.
There is a very productive collaboration with the U. Karlsruhe,
which is developing and using the Sather-K dialect.
Excellent progress is also being made on the parallel version of
Sather, pSather and on its applications.In the fall of 1994, the
project was joined by M. Phillipsen (Karlsruhe) and C. Fleiner
(Fribourg) and both have made major contributions. In the fall of
1995, H. Klawitter(Munster) and A.Jacobsen(Karlsruhe) also joined the
project. Boris Vaysman a UCB doctoral student will be doing his
dissertation on pSather as is David Stoutamire. pSather has
been designed to support easy parallelization of a wide range of
codes, especially those with irregular data and control
structures. An earlier (thesis) implementation obtained good
results on the CM-5 but was not suitable for general use. The
current implementation has been part of the general Sather
release since Ver. 1.0.6 in May 1995, but has not yet been
ported to any MPP. One goal achieved this year is a
fully usable pSather on the Meiko CS2. The CS2 is a European
design and was chosen because of its size, its clean operating
system and the relatively little effort it would appear to
require for us to port. Another important achievement was the purchase
and installation of the Myrinet high-speed network and porting pSather
to this platform as well. Claudio Fleiner played the key role in
both these porting efforts.
In addition to system building and deployment, the PSather group has
been active in research. At
the system level are a number of questions concerning automatic
and semi-automatic placement and migration of data and code.
This is an active area of our research and our goal is to
support a wide range of applications. In fact, a major goal of
the project is to significantly extend the range of computations
that are practical on MPPs; a major focus of the research is to
develop tools and classes that will make efficient use of the
machine.
ScaLAPACK (J. Demmel)
ScaLAPACK
is a library of parallel linear algebra routines
It achieves portability by doing all
communication using the BLACS (Basic Linear Algebra Communication Subroutine
library), which is in turn has been implemented using MPI, PVM and other
lower level libraries. We have produced an Active Message version of the
BLACS, which has let us successfully run the ScaLAPACK test codes in Castle.
We are continuing to work on the Split-C-to-ScaLAPACK interface, to permit
calls to ScaLAPACK on arrays defined in Split-C. A description of this
work will appear in the MS thesis of M. Ivory (in progress).
Much of our work has depended
on the availability of high performance Basic Linear Algebra Subroutines.
These are typically commercial products, specific to each platform,
and often expensive;
this is a major reason LAPACK has not yet been integrated into
packages like Matlab. We are addressing this problem by producing
a system, called PHiPAC, for automatically producing high-performance
BLAS for any RISC architecture. For example, our system has automatically
produced matrix-multiplication routines that on average outperform IBM highly
tuned ESSL library, as well as SGI's similar library.
The same software has produced 90\% of peak performance on
Sparcstation-20/61 and HP 712/80i. An alpha release of the software
is available at
http://www.icsi.berkeley.edu/~bilmes/phipac/
.
Future work will involve producing the entire suite of BLAS routines.
This work is jointly funded by the LAPACK project (DOE and NSF).
Parallel Applications
In addition to the parallel applications discussed in last year's
progress report (Phyllogeny Problem, Cell Simulation, and GATOR, a Gas, Aerosol, Transport, and Radiation Chemistry model), we have developed several new
parallel applications.
Inktomi (E. Brewer)
We have developed a new application to investigate the development of
scalable, reliable Web servers. Inktomi
is parallel WWW search engine built using
Active Messages.
It began as a course project by P. Gauthier in J. Demmel's parallel
computing course. Prof. E. Brewer guided the design.
The initial demonstration was an order of magnitude faster than
existing search engines in the same capacity range, millions of documents,
on a much more cost-effective platform.
This project was so successful, that we decided to dedicated a portion
of NOW-1 to its use, so that we might obtain true usage characteristics.
The Inktomi Search Engine has been running non-stop since October 1995.
The project has also developed a scalable Web crawler, which uses NOW-1 to
crawl at a rate of roughly a million documents per day. In December we
loaded a database of 2.8 million documents, making it the largest on-line
web database. More importantly, the new database was brought on-line with
no downtime. Since that time, we have conducted several upgrades and tests,
such as software upgrades and powering down the internal network without
downtime. This is a clear demonstration of the reliability, in addition
to the cost-effectiveness and scalability of the Titan approach.
We have demonstrated the integration of Inktomi with Glunix, by allowing
Inktomi to acquire the memory of idle nodes as a remote paging device.
Electromagnetic Simulation (A. Neureuther)
TEMPEST is a parallel electromagnetic simulator built in Split-C
by Prof. A. Neureuther's group in the Berkeley EECS Dept. It is intended
for production runs in understanding scattering from nonplanar polysilicon
features in printing gate tips as they cross the field edge.
TEMPEST simulates a 3-dimensional domain of
grid points, and the electric and magnetic field values at each grid point
are calculated iteratively. We anticipate running 14,000,000 node
problems at a density of 14 nodes per wavelength.
For the parallel version, the 3-D grid is partitioned among processors
along the xz and yz planes
and each processor holds the field
values for the grid points that it owns. Each grid point only relies on
its closest neighbors to do its computation, so the only interprocessor
communication required is at the planar interfaces between blocks owned
by each processor; this gives rise to the nice ``surface-volume effect''.
Moreover, the simulation is very regular
in its behavior, so each processor knows exactly which processors it
needs to communicate with, and when; using split-phase communication
provided in Split-C, each processor can start fetching nodes from
neighboring processors, do completely local computation while the nodes
are arriving, and then compute boundary nodes when the neighbor's nodes
have arrived. Due to the surface-volume effect, communication should
largely overlap computation for large problems.
Connected Components (D. Culler)
A Split-C implementation of a novel algorithm for finding connected components
of graphs has been implemented and tested on the
Cray T3D, the Meiko CS-2, and the Thinking Machines CM-5 using a class of graphs derived
from cluster dynamics methods in computational physics.
On a 256 processor Cray T3D, the
implementation outperforms all previous solutions by an order of magnitude.
Out of Core Algorithms (J. Demmel, K. Yelick)
We have completed an out-of-core LU decomposition code in Split-C,
as a case study of typical large applications that require I/O
to secondary storage for the intermediate and final data.
We have chosen 2 layouts that allocate a blocked matrix into processors
in row-cyclic manner and developed a simple performance model
based on a startup cost and bandwidth for disk access. The
performance is modeled for the 2 layouts and validated against
experimental results for relatively small matrices. The model
indicates that a left-looking algorithm is more efficient than
right-looking ones, since write access is limited only in the
current block column when the permutation of the rows is postponed.
A report on this work is underway.
Cell Simulation (K. Yelick)
Further progress has been made in our study of cell simulation.
``Performance Modeling and Composition: A Case Study in Cell Simulation,''
S. Steinberg, J. Yang, and K. Yelick, IPPS 1996,
discusses case study in the use of performance modeling for
parallel application development, with a biological cell simulation
from C. Peskin and G. Oster as our target application.
It is shown that a simple performance model is
adequate for determining data layout for arrays and linked structures,
and the model validated against experimental results for some
application kernels. The importance of optimizing across
program components using information about machine performance and
input characteristics is quantified. The cell simulation application has two
phases, one regular and one irregular. The model closely predicts
actual performance within the regular phase and allows for qualitative
design comparisons in the irregular one. The resulting application is
written in Split-C and runs on multiple platforms.
Scheduling (J. Demmel, K. Yelick)
In addition to the multijob scheduling work of Andrea Dusseau described above,
we analyzed the utility of mixed (both data and task) parallelism in a variety of
scientific applications. Several of these problems
(including eigenproblems, sparse Cholesky, and others) have a divide-and-conquer
structure, with task parallelism available from the subtrees of
the divide-and-conquer tree, and data parallelism within the tree nodes.
There are a variety of ways, both simple and complicated to assign processors
to various parallel jobs. In the paper
``Predicting the Benefits of Mixed Data and Task Parallelism''
by S. Chakrabarti, J. Demmel and K. Yelick,
Symposium on Parallel Algorithms and Architectures, July 1995,
we developed a simple scheduling policy that gets close to optimal speedup.
This policy can be implemented by a task-queue like structure similar to one
in Multipol, and will be part of the nonsymmetric eigensolver in the next
ScaLAPACK release.
Shell: Multimedia Component
Networking for Continuous Media (D. Ferrari)
The Tenet group has made available the source code of its Real-Time
Protocol Suite 1. The suite consists of three protocols (RMTP and RTIP
for data delivery, RCAP for guaranteed-performance channel
establishment and teardown), which have been designed to coexist with
the Internet protocols. The source code can be freely used for
educational and research purposes without a license; its commercial
exploitation requires obtaining a license from the Regents of the
University of California, who own the copyright to it.
While RCAP runs
in user mode, RMTP and RTIP are part of the kernel; the code being
distributed can be used on Ultrix 4.2A, Irix 4.0.5f, and BSD/OS
2.0. An OSF-1 version is in preparation.
Deadalus/BARWAN Wireless Infrastructure (E. Brewer, R. Katz)
We have deployed 6 base stations (infrared as well as radio frequency) on
the 3rd, 4th, and 6th floors of Soda Hall, providing wireless connectivity
to the major classrooms and auditoria in the building. We have implemented
efficient handoff algorithms so it is possible for a user with an
appropriately equiped laptop computer to move throughout these building
spaces while maintaining continuous connectivity. We have demonstrated the
infrastructure's ability to support users in their viewing of multicast
video sessions of Berkeley research seminars (in particular, Professor
Larry Rowe's Multimedia Seminar) anywhere within the covered portions of
the building. Despite the latency sensitive nature of the video
transmissions, we have demonstrated real-time handoffs without perceptable
loss of quality or interruption of service. We have also demonstrated the
seamless handoff between IR covered rooms and the overlaying RF
infrastructure. The next major steps are to integrate the existing
infrastructure with the Metricom packet radio network which has been
deployed on the Berkeley campus and is poised for deployment in the City of
Berkeley.
Continuous Media Toolkit (L. Rowe)
Development has continued on the Continuous Media Toolkit. We have
built CMPlayer, a continous media playback application that can create
live connections to remote video file servers and stream synchronized
video and audio data across the Internet WITHOUT downloading the
entire file. It can also be used to play local audio and video files.
The CMT source tree as well as pre compiled binaries for the various
CMT executables and CMPlayer are available from the CMT page. This work
is now widely used with the Titan environment, and within the newly
formed Berkeley Media Research
Center.
BMRC also received an NSF Academic Infrastructure Grant to develop a
video storage system (i.e., video server and tertiary storage backup)
and high-speed network for deliverying stored and live video material
to researchers in many departments at Berkeley
(e.g., EECS, Mechanical Engineering, School of Education, School of
Information and Systems, etc.) including Titan researchers.
This high-speed network is connected to the Titan network to deliver
real-time video to desktops and classrooms within Soda Hall. More
information on the video storage system is available
here.
Driving Applications
GATOR (J. Demmel)
As part of a NASA HPCC Grand Challenge project, we have
continued the design and implemention of
a parallel atmospheric chemical tracer model, that will
be suitable for use in global simulations:
GATOR.
To accomplish this goal,
our starting point has been an atmospheric pollution model that was
originally used to study pollution in the Los Angeles Basin. The model
includes gas-phase and aqueous-phase chemistry, radiation, aerosol
physics, advection, convection, deposition, visibility and
emissions. The potential bottlenecks in the model for parallel
implementation are the compute-intensive ODE solving phase with load
balancing problems, and the communication-intensive advection
phase.
We have developed an implementation and analyzed performance results on a
variety of platforms, with emphasis on a detailed performance model we
developed to predict performance, identify bottlenecks, guide our
implementation, assess scalability, and evaluate architectures.[DeSm95]. An
atmospheric chemical tracer model such as the one we describe in this
paper will be one component of a larger Earth Systems Model (ESM),
being developed under the direction of C. R. Mechoso of UCLA,
incorporating atmospheric dynamics, atmospheric physics, ocean
dynamics, and a database and visualization system.
Dynamic simulation with IMPULSE (J. Canny)
John Canny and graduate student Brian Mirtich continued to develop
software for real-time dynamic simulation with full-friction modeling
of impacts. The collision detection code used in the system has been
available via anonymous FTP since July 94
Here.
The first general publication of the simulator was given in the 1995
Symposium on Interactive 3D Graphics in Monterrey. A second paper
titled ``Hybrid Simulation: Combining Constraints and Impulses''
appeared in the Proceedings of the First Workshop on Simulation and
Interaction in Virtual Environments in Iowa, July 1995. MPEG and AVI
Movies of the simulator are available online Here.
A parallel version of Impulse was written in Split-C as a project
in J. Demmel's graduate parallel computing seminar.
Over the last year, the following tasks were completed:
Click here
for a simulation of a pool break.
The Berkeley WALKTHRU Project (C.H. Sequin)
The Berkeley WALKTHRU Project continues to be a direct
beneficiary as well as one of the driving applications of the
expanding Titan environment. During the last few years we have
developed a fully furnished building model of Soda Hall, our new
computer science building. The model is now composed of over two
million polygons. Due to sophisticated algorithms for space
subdivision and visibility precomputation [Funk96] it can be rendered
at 20-30 frames per second on high-end workstations with
special-purpose graphics hardware. Since few people can afford these
powerful rendering systems, part of our research aims to investigate
how this rendering task can be accomplished on a more general-purpose
computing resource, such as a network of workstations, or on future
wireless, hand-held "DynaBooks" or "InfoPads," or even on a PC
attached to the World Wide Web.
The emergence of VRML2.0 gives us some hope of having a generally accepted
format in which a complex, partially interactive model can be described
so that it can readily be sent over the net and rendered on a wide
variety of platforms.
A first task will be to convert the rather large model from its current
description in Berkeley UniGrafix3.0 to the emerging VRML2.0 format.
We have just completed a converter from UniGrafix to Inventor.
Betting that the winning VRML2.0 proposal will be ``Moving Worlds''
proposed by SGI and others, we hope to soon have our model also
available in an acceptable VRML format.
The next more difficult task will then be to find a way to break the model
into manageable chunks that can be transmitted over the net on demand,
so that distant users can ``visit'' various rooms without having to download
the complete model, which requires several hundred Mbytes of storage.
During the last two years we have also made our Soda Hall WALKTHRU model
interactive.
The user is now able to modify the contents of the building, move furniture
around, hang pictures on walls, and clutter desk tops with sundry items.
The framework of mechanisms that permits easy and natural manipulation of
these items with a simple 2D mouse, is called "Object Associations" [Buko95].
It implements a combination of almost realistic-looking
pseudo-physical behavior and idealized goal-oriented properties,
which disambiguate the mapping of the 2D cursor motion on the display screen
into an appropriate object motion in the 3D virtual world and
determine valid and desirable final locations for the objects to be placed.
We are continuing our study of appropriate user interfaces to such virtual
environments through ordinary workstations and through "InfoPads."
In particular, we are looking for ways to disambiguate the limited expressibility
of user-gestures with a 2D mouse in order to control the six degrees of
freedom of rigid objects in 3-space without the need for
expensive and cumbersome devices such as the "DataGlove."
We also want to extend the range of interactions with such virtual
environments to the point where the model can be shared over the network
and where several participants, sitting at different workstations,
can explore or modify the model in a joint interactive session.
In a special prototype version of the program
covering a simpler toy-world of plain, block-like objects,
we have experimented with a simple collision detection mechanism
based on the Lin-Canny closest feature detection algorithm.
This algorithm is very efficient but requires that the whole world
be described as a collection of unions of convex parts.
Decomposing an arbitrary object into such a form is a complex task
and can lead to potentially very inefficient descriptions.
We are looking for automated ways of decomposing arbitrary objects
into near-spherical "blobs" that can be approximated
by their convex hull which will then provide efficient tests
for collision detection.
We can then utilize this efficient collision detection to allow a user
to interactively refurnish the interior of a building model.
Our object simplification approach is based on a conservative
voxelization of an object with a voxel size commensurate
with the precision required for the task at hand;
this provides at the same time the required spatial localization
as well as an adjustable degree of low-pass filtering.
This step is followed by additional filtering that reduces
the object to a skeletal representation.
The skeleton characterizes the shape features of the object
and is used to identify candidates for subdivision
in order to arrive at a decomposition into compact "blobs"
that are particularly efficient for collision detection.
Serendipitously it turns out that the very same algorithm
also is useful to solve another important and potentially difficult
task for us.
Some models we might receive for an interactive walkthrough
exploration may not already be well structured into rooms
with explicit adjacencies and connectivity through portals.
Finding the desired coherence in a "soup" of several million polygons
can be a rather daunting task.
By sending all these polygons through the above voxelization process
at a suitably chosen spatial resolution,
complementing the final set of occupied voxels,
and then skeletonizing this complex object,
we can use the same techniques mentioned above to find the blobs
that represent the interiors of individual rooms
and the portals that define the connections between them.
Some of these computations can obviously get somewhat extensive
for complex building models; -- that is where the integrated computing
power of the TITAN environment comes in quite handy.
The WALKTHRU project is not just aimed at discovering techniques
for making interactive models of complex buildings.
As a driving force we want to create an ever more complete model
of Soda Hall that is actually useful to its occupants
for management and maintenance purposes.
We continue to integrate more of the design and construction
information into the existing geometrical model.
This past year we have been working on a prototype of a database
that captures much of the idiosyncratic design information
that often gets lost during the process of finalizing a design
and then construction the actual building.
We have created interlinked trees of category nodes
concerning a variety of design issues and building systems
which can be accessed and perused over the World Wide Web.
Users of this database can add their own thoughts and comments
as "Issues" to any of the category nodes;
these will then become visible to all future database surfers.
We are currently in a collaborative effort
with a group in the Architecture department in the College of
Environmental Design to restructure this experimental prototype
and to put it on a more sound organizational footing.
This prototype database can be accessed from the Soda Hall home page
[SODA].
As one example how such building models can be put to practical use,
we are creating -- under sponsorship of NIST (National Institute of
Standards and Technology) -- a visualization and manipulation front end
for their CFAST fire simulator.
This fire simulator models the spread of a fire through a building
by solving the appropriate physics equations for each room,
iteratively updating various state variables as a function of time,
and exchanging some quantities such as smoke and heat
with adjacent rooms through the intervening portals.
It turns out the data structure needed is very similar
to the data structures that we build inside our building WALKTHRU
models in order to quickly calculate potential visibility.
We have done a first integration pass between the two programs
and are now able to start a fire interactively from within
a virtual WALKTHRU environment and then to observe the results
-- so far in simple symbolic form -- in the same setting.
We are currently working at making the visualization more realistic
-- which will make strong use of texture mapping
and will also consume a fair amount of compute cycles.
One lesson learned over the last few years is that it is tedious
and labor intensive to create these building models.
People will only use such 3D models for visualization of construction
projects or for what-if studies concerning fire safety,
if we can find easier ways to create such models.
Starting from the assumption that most people may already have
floor plans of their buildings (hopefully in computer drafted form),
we have created a system that procedurally
generates a simplified 3D model of the corresponding building,
therefore reducing required human effort.
In order to be used for this purpose, floor plans must be cleaned
up and analyzed, by correcting geometric errors and then grouping
the various geometric entities into meaningful objects such as rooms,
doors, and windows.
The approach taken locates individual rooms,
derives consistent contours for each one,
identifies the locations of doors and windows,
and then extrudes all wall segments to their predescribed heights,
inserting door and window models where needed.
The addition of floor and ceiling polygons results in
a consistent solid model of the building.
This 3D model may be edited in order to adjust some height information,
such as the exact dimensions of doors and windows.
Stairs are generated by a separate stair generator,
and are then inserted into the 3D model [Lewi94].
While this first model does not have many decorative details,
it is useful for fire simulation or for a prospective client
to study the internal organization of the space in a proposed project,
before the architects have invested many work months
on a detailed design.
With these tools, we were able to generate a 3D models of two floors
of Soda Hall from the original 2D floor plans in less than an hour.
The hardware and software infrastructure provided by the TITAN
project plays an important role in the rapid development
of these prototype demonstrations.
REFs:
[Lewi94]
R. W. Lewis:
``StairMaster: An Interactive Staircase Designer,''
pp 27-36 in "Procedural Modeling,"
Tech Report No. UCB/CSD-94-860, Dec. 1994.
[BuSe95]
R. Bukowski and C. H. Sequin:
``Object Associations: A Simple and Practical Approach to Virtual 3D Manipulation''
Proc. 1995 Symposium on Interactive 3D Graphics, Monterey, April 10, 1995.
REFs:
[Buko95]
R. Bukowski:
``The WALKTHRU Editor: Towards Realistic and Effective Interaction with Virtual
Building Environments,''
Tech Report No. UCB/CSD-95-886, Nov. 1995.
[Funk96]
T. A. Funkhouser, S. J. Teller, C. H. Sequin, and D. Khorramabadi,
``UCB System for Interactive Visualization of Large Architectural Models,''
Presence, Spring 1996.
[WALK]
The WALKTHRU project home page.
[SODA]
The Soda Hall home page.
OPTICAL: OPtics and Topography Involving the Cornea And Lens (B. Barsky)
This project is studying the cornea, the front part of the eye that is
responsible for three quarters of the light refraction in the eye.
Visual correction through contact lenses or recently developed corneal
surgeries require precise information about the shape of the
cornea. Through the use of geometric modeling and scientific
visualization, this project is developing sophisticated techniques to
provide improved shape representations of patients' corneas.
An OPTICAL Software Visualization Suite has been developed and
is available at http://http.cs.berkeley.edu/projects/optical/suite.html.
See
http://http.cs.berkeley.edu/projects/optical/algorithm.html for visual results from our new algorithm.
Images
-
Barsky, Brian A. (1996) "Computer Aided Contact Lens Design and Fabrication
Based on Spline Mathematics", Contact Lens Spectrum, Vol. 11, No. 4,
April 1996, pp. 39-49
-
Halstead, Mark A.; Barsky, Brian A.; Klein, Stanley A.; and Mandell, Robert B. (1995)
"A Spline Surface Algorithm for Reconstruction of Corneal Topography from a
Videokeratographic Reflection Pattern",
Optometry and Vision Science, Vol. 72, No. 11, November 1995, pp. 821-827.
-
Halstead, Mark A.; Barsky, Brian A.; Klein, Stanley A.; and Mandell, Robert B. (1996)
"Reconstructing Curved Surfaces From Specular Reflection Patterns Using Spline
Surface Fitting of Normals", ACM/SIGGRAPH '96, New Orleans, 4-9 August 1996,
to appear.
-
Klein, Stanley A. and Barsky, Brian A. (1995) "Generating the Anterior Surface
of an Aberration-free Contact Lens for an Arbitrary Posterior Surface",
Optometry and Vision Science, Vol. 72, No. 11, November 1995, pp. 816-820
Digital Libraries
(R. Wilensky, D. Forsyth, J. Malik)
The
Digital Library Project has made substantial progress toward providing
easy access to massive stores of information, and has heavily utilized the
Titan Core computing infrastructure. In the
natural language processing technology for digital libraries area,
preliminary algorithms developed for text segmentation ("TexTiles")
automatic topic characterization,
geolocating text ("GIPSY" - Plaunt & Woodruff) and
disambiguation and heuristic reference.
User studies in the digital library project indicate clearly that users
wish to query large collections of images by the objects present in
those images; requests to the DWR include topics such as ``a scenic
picture'' or ``children of all races playing in a park.''
The sheer bulk of available collections of images requires that
image segmentation and content annotation be done automatically.
Furthermore, images need to be described at a variety of levels;
thus, a user should be
able to query for images using:
-
object content - for example, by explicitly looking for
pictures of construction equipment, or pictures containing horizons;
-
Appearance properties - for example, by explicitly looking
for images with many small yellow blobs.
properties that are useful in building object recognisers.
In particular, our approach to object recognition is to construct a sequence
of sucessively abstracted descriptors, at an increasingly high level,
through a hierarchy of grouping processes.
We have implemented a program that can classify images according to
the presence of ``blobs'' of colour of various sizes and spatial
distributions. For example, an image of a field of flowers might
contain many small yellow blobs.
Such cues provide extremely useful
information about content.
We have also implemented a program that can tell whether an image
contains a horizon or not. Various combinations of coloured blob
queries, horizon queries and text queries correlate extremely strongly with
content in the present Cypress database. This query engine is
can be searched on the World Wide Web, at
the Berkeley Digital Library
image query site . In particular, one can
either construct a query from scratch using coloured blob properties,
horizon properties, and text properties, or use concept queries that
have been constructed in advance. For example, there is an ``orange
fish'' query that is obtained by looking for the presence of orange
blobs, the absence of large yellow blobs, and the word ``fish.''
We have built a number of demonstration programs to
refine this technology; this material will be delivered into Cypress
as it matures.
Many image regions have an internal coherence that is not well
described by simple colour properties. For example, a plaid shirt may
display a variety of coloured patterns that repeat in a relatively
well-controlled way. However, foreshortening effects mean that a
pattern that repeats regularly on a surface may not appear regular
in an image. We have built a program that can segment image regions
that are periodic on surfaces; the program finds a seed pattern, and
then compares this seed with neighbouring patterns while accounting
for distortion.
While trees have considerable geometric structure, it is unrealistic
to expect to match individual trees. Instead, one must consider types
or classes of tree, where the types are defined by appearance
properties. By representing trees as translucent, rotationally
symmetric volumes containing small oriented elements, we have implemented a
program that can mark the outline and axis of trees in simple images.
The program then recovers a representation for the image of the tree;
this representation appears to distinguish usefully between distinct
classes of tree.
An important query topic is whether an image contains people. People
are relatively easy to find using our approach, if they can be
segmented. In particular, people consist of a number of segments of
relatively simple shape, assembled in a predictable fashion. We have
built a grouper that can take image edge segments and assemble them
into potential limb segments; these limb segments are then assembled
into limbs, and limbs into girdles. Segmentation is the main
obstacle, as it can be hard to find limb segments in images of
people wearing patterned or textured garments. We have demonstrated
the feasibility of the approach by refining the query to look for
naked people, as skin has highly uniform colour and texture
properties; in a test involving 4289 control images drawn from many
sources, and 565 very general test images, our implementation
of this query marked approximately 43 % of the test images and only
4.2% of the control images.
Our existing program concentrates on legs; a more catholic set of
features should improve the recall.
Papers:
-
Fleck, M.M., Forsyth, D.A., and Bregler, C., "Finding
naked people," Proc. European Conf. on Computer Vision}, 1996.
-
Leung, T. and Malik, J., "Detecting, Localizing and
grouping repeated scene elements from an image,"
{\em Proc. European Conf. on Computer Vision}, 1996.
-
Forsyth, D.A., Malik, J., Fleck, M.M., Leung, T.,
Bregler, C., Carson, C., and Greenspan, H., ``Finding objects by
grouping,'' (accepted for publication, 2nd International workshop on object
representation), 1996.
Autonomous Vehicle Navigation (S. Russel, J. Malik)
We have made significant progress in applying stereo vision
algorithms to the problem of autonomous vehicle navigation on
highways. The project consists of two parts: lane extraction and
obstacle detection.
Our lane extraction system is based on a parameterized model for the
appearance of the lanes in the images. This model captures the
position orientation and curvature of the lane as well as the height
and inclination of the stereo rig with respect to the road. The lane
tracking algorithm applies a robust estimation procedure to recover
the parameters of the model from extracted lane features in real-time.
The real time stereo system that we are experimenting with has been
specifically designed for use in a highway navigation system. The
algorithm proceeds by correlating regions demarcated by intensity
edges in the left and right images. This approach identifies and
localizes obstacle regions in the scene rather than isolated points.
These algorithms have been implemented on a network of TMS320C40 DSPs.
References can be found at
http://http.cs.berkeley.edu/projects/vision/vision_group.html.
Integration of Theory and Practice (M. Blum, J. Canny, R. Karp, A. Ranade, A. Sinclair)
The Titan infrastructure has served to facilitate the integration of
theory and practice in many areas.
- Torsten Suel has developed and test-run parallel
codes for N-Body simulations (Barnes-Hut and adaptive FMM algorithms).
written on top of a BSP
message-passing library.
- Satish Rao (visiting Prof) has continued developing applications for the
green BSP library. The results will be reported in SPAA.
He used the Titan facilities to continue the development of codes that
provide guidance to heuristic VLSI layout programs. A collaborator at
NEC Central Research Labs is experimenting with using the output in
his heuristic layout program.
- Hal Wasserman (with M. Blum) have used the Titan facilities for testing
hypotheses in
(i) the behavior of iterated functions and (ii) testing
the algebraic properties of certain sets of boolean vectors.
- Daniel Wilkerson (with A. Ranade) has used Titan facilities to
develop simulations of constant size queue packet routing. With low
buffer size, the interactions of packets in a system like this create
dependencies across the entire system. The local behavior of the system is
easily controlled by the engineering of the routing switches; However, we
really want to know what global behavior arises from this local behavior.
For example, total network throughput, and probabilistic upperbounds on
maximum packet delivery time are global measures of the system behavior we
would like to be able to say something about. One global phenomenon that
arises naturally is traffic jams. Saying something about the process by
which they arise and dissolve would be very useful. However, even
conjecturing this behavior is difficult, since it is occurring in a very hard
to visualize space, like a butterfly. We have used the machines here to
simulate these traffic jams. In particular I have simulated the behavior of
heavily loaded packet routing with uniform random destinations being routed
in a greedy fashion on a butterfly. Of particular interest is how space
propagates through a previously locked-up jam as it begins to dissolve.
>From these simulations we have a much clearer idea of the conjectures we are
trying to prove.
- Ari Juels (with A. Sinclair) has used these facilities for
investigating Genetic algorithms (GAs), which are a method of approaching
analytically intractible problems with a minimum of problem-specific
information. Their flexibility, combined with the intellectual appeal
of their motivation from Darwinian evolution, has made GAs a very popular
function optimization method. Their behavior, though, like that of real
evolutionary systems, is hard to analyze precisely. To show that GAs are
effective, a testbed of substantial and interesting problems is an
absolute requirement. What, though, does it mean for a problem to be
substantial? In the early stages of my research, I aimed to broach
this question experimentally. A review of the literature of the GA
community revealed that many of the so-called "hard" problems intended
by researchers to demonstrate the power of the GA, are not really hard
in practice: simple hill-climbing methods often do better. At present,
I am studying a leaner, mathematically simpler GA known as the
Equilibrium Genetic Algorithm (EGA).
The EGA has attractive theoretical properties; my most recent
experiments are directed at investigating its performance in practice.
Comparing algorithms on hard problems in a convincing,
statistically significant way requires substantial computing power. I
often find myself using half-a-dozen workstations in tandem for
experiments lasting several weeks. The cluster of HP
workstations, because of their accessability and mutual compatability,
has therefore become the mainstay of this experimental work.
- Michael Mitzenmacher (with A. Sinclair) has conducted a study
of randomized load balancing. Mathematically,
the problem can be thought of as follows: there is a large supply of jobs,
that must distribute themselves into a large set of processors. There may
be many goals for a distribution strategy, such as minimizing the largest
number of jobs on a processor and minimizing the amount of coordination the
jobs must undertake in distributing themselves. By performing simulations,
we can gauge which strategies appear most effective and gain insight to
their behavior. The simulations thus help determine what
strategies are worth studying and analyze the behavior of these strategies.
It is important to be able to run large simulations, since often one
has to look at reasonably big systems before patterns become apparent.
- Geoff Zweig (with Karp) has studied
Byesian network, a directed acyclic graph in which the nodes
represent random variables,
and the arcs represent conditional dependencies. The probability of a
variable taking a specified value is determined by the values of
its predecessors in the graph. These conditional probabilities are stored
in conditional probability tables associated with each node.
Given values for a subset of the variables in a network, the goals of
probabilistic inference are:
1) To determine the probability that the Bayesian network generated the
observations.
2) To determine the marginal probabilities of each of the other variables.
3) To determine the likeliest assignment of values to the other variables.
The problem of making such inferences is NP-hard, and involves computing sums
with an exponential number of terms. We have attacked this problem by
implementing efficient summation procedures, and by using stochastic simulation
to approximate the desired quantities. Both methods are computationally
intensive, and have benefited from the Titan facilities.
- Paul Horton (with Canny) has computed globally optimal
solutions to instances of what is know as the local multiple string
alignment problem. Local multiple string alignment is of interest to
biologists because it can often be used to deduce functionally
important local regions of DNA or proteins. The problem is NP-hard but
I was able to show that for problem sizes which come up in practice a
branch and bound algorithm can sometimes find a provably optimal
solution. For the hardest problem, the program needed 72 hours of
wall-clock time to finish. Thus the computing resources providing by
Titan were instrumental for that study, the results of which were
published in the Proceedings of the 1996 Pacific Symposium on
Biocomputing in Hawaii.
- Dan Spielman (postdoc) has investigated error-correcting code and
spectral partitioning. There are many parameters that effect the
performance of error-correcting codes. To find the
optimal settings, we test the performance different settings
against millions of error patterns.
Our analysis of spectral partitioning (with Shang-Hua Teng)
was inspired by observing the performance of spectral
partitioning algorithms on numerous graphs. Only after examining
the spectra of many graphs were we able to formulate the
conjectures concerning spectra of planar graphs which we later
proved (UCB tech report UCB//CSD-96-898).
- Alistair Sinclair (Prof) has
analyzed Monte Carlo
algorithms in statistical physics. These are widely used to obtain
precise numerical estimates of important parameters of various
physical models, such as the Ising model or the self-avoiding walk
model for linear polymers. This research aims to quantify, as tightly
as possible, the number of Monte Carlo steps required to obtain a
desired accuracy and confidence in the final numerical answer, and
to develop new algorithms for which this number of steps is small.
Computer experiments have been essential in several ways to this
research, most notably in the formulation and testing of conjectures
concerning the combinatorial properties of the models under
investigation, and in the implementation of the final algorithms.
For example, we have successfully computed rigorous statistical
estimates of the number of self-avoiding walks of length 50; previously
this had been possible only for lengths up to about 30.
Education
We have developed a significant amount of educational
material related to Titan.
First, J. Demmel developed a
fully on-line course,
CS 267
, on ``Applications of Parallel Computers'',
offered every spring.
It covers parallel architecture, software, and applications.
J. Demmel taught it as an NSF-CBMS short course in June 1995,
and it will be used as a textbook at Stanford and UCSB next semester.
SIAM will be publishing a paper version of the text.
D. Culler developed another class,
CS 258, on
``Parllel Computer Architecture''
in collaboration with A. Gupta and J. P. Singh of Stanford.
The text book is under contract to Morgan-Kaufman.