Once the learned set has been read in from the image file and its properties recognized, it can be written out to a "learn" file. This file stores the properties of the learned characters in abbreviated form, eliminating the need for retaining the images of the learned characters, and can be read in very quickly.
Sample image file and text for learning
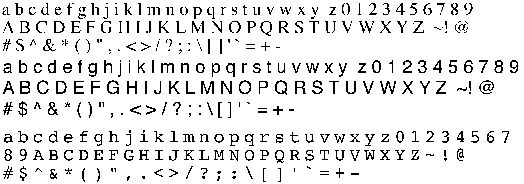
abcdefghijklmnopqrstuvwxyz0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZ~!@
#$^&*()"",.<>/?;:\[]'`=+-
abcdefghijklmnopqrstuvwxyz0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZ~!@
#$^&*()"",.<>/?;:\[]'`=+-
abcdefghijklmnopqrstuvwxyz0123456789
ABCDEFGHIJKLMNOPQRSTUVWXYZ~!@
#$^&*()"",.<>/?;:\[]'`=+-
Character Extraction
Character extraction has three phases:
- Detection of lines of text
- Detection of connected components
- Projection upward and downward to grab dots on "i"s and "j"s

Line Detection
To detect lines of text (which is later useful in determining the order of characters and possibly their layout on the page) we do a horizontal projection of the page. Our original plan was to detect line breaks using some kind of statitistical analysis, but for now, adjacent lines in the image having a very small number of pixels constitute a line break. Noise can decieve this simple algorithm, but adjusting the NoiseTolerance global variable can usually allowthe user to overcome this shortcoming.
Component Extraction/Projection Above and Below
 To extract the connected components from each line, OCRchie, starting at the upper right corner of each line, removes touching intervals of black pixels from the run-length-encoded representation of the image until nothing more connected can be found. The extraction routine then looks upward and downward to see if there are possible "extra parts", such as the dot on an 'i', hanging directly above or below the component. It ignores components that are only minimally above or below the extracted component, as when the tail of a 'y' extends below the letter preceding it. The projection does not occur if the region has been marked as an equation in the user interface.
To extract the connected components from each line, OCRchie, starting at the upper right corner of each line, removes touching intervals of black pixels from the run-length-encoded representation of the image until nothing more connected can be found. The extraction routine then looks upward and downward to see if there are possible "extra parts", such as the dot on an 'i', hanging directly above or below the component. It ignores components that are only minimally above or below the extracted component, as when the tail of a 'y' extends below the letter preceding it. The projection does not occur if the region has been marked as an equation in the user interface.

Character Property Extraction
After isolating what are believed to be the characters in a document,
we determine a set of properties for each of these characters. The
property set is currently a 29 -element vector, but can be modified to accomodate
more or less features if necessary. The first 25 elements are the ratio
of black:white (grayscale) in each of 25 equal-sized subregions of the c
haracter.
Property 25 is the grayscale accross the top 1/2 division.
Property 26 is the grayscale accross the bottom 1/2 division.
Property 27 is the width/height ratio again scaled to (0-255)
Property 28 is Indicator of a vertically disjoint character
like i and j.
Comparison of Learned and Extracted Characters
After extracting the individual characters in a document and determining their properties, we compare them to the learned set. The comparison algorithm is simple: it sums the squares of the differences between each property in the extracted character and each property in the learned character, returning a "Confidence". Initially, we compared each extracted character to the entire linked list of learned characters, but in the interest of speed, we modified this slightly to classify characters in relation to the baseline of their line of text. Letters like "g", "j" & "y", which extend below the baseline are in one group, tall letters, such as "l" and "T" are in another, short characters, like "a" and "c" another, and floating characters, such as "'" and "^" are in the last. Once classified, an extracted character is compared to learned characters which are in the same group. If no good match is found, the extracted character is then compared to the other learned characters, regardless of group.
Additional Operations on Low-Confidence Matches
Because we found that some characters made it past the original character recognition algorithm, we deemed it necessary to perform additional operations on poorly recognized characters.
Splitting Wide Characters
The most obvious cause of misrecognition in our original program was linked characters. An "r" would just barely touch an "i", and the character would be recognized as an "n". To alleviate this problem, when encountering a low confidence match on a wide character, OCRchie will split the character at its most narrow point. If the confidence of the left side of the split higher than before, the character is assumed to be joined, and the split remains. Otherwise, the split is rolled back.
This algorithm could possibly cause problems with something like "mi"-- with a poorly scanned "m", the joined character could be broken in the middle of the "m", find an "n", and do something unpredictable with the remnants of the "m" and the "i".
Merging Narrow Characters