David Wagner Bruce Schneier John Kelsey
University of California, Berkeley Counterpane
Systems
daw@cs.berkeley.edu {schneier,kelsey}@counterpane.com
May 30, 1997
This paper analyzes the Telecommunications Industry Association's
Cellular Message Encryption Algorithm (CMEA),
which is used for confidentiality of the control channel
in the most recent American digital cellular telephony systems.
We describe an attack on CMEA which requires 40-80 known plaintexts,
has time complexity about ![]() -
- ![]() ,
and finishes in minutes or hours of computation on a standard workstation.
This demonstrates that CMEA is deeply flawed.
,
and finishes in minutes or hours of computation on a standard workstation.
This demonstrates that CMEA is deeply flawed.
Keywords: cryptanalysis, block ciphers, cellular telephone
As the US cellular telephony industry has boomed, the need for security has increased: both for privacy and fraud prevention. Because all cellular communications are sent over a radio link, anyone with the appropriate receiver can passively eavesdrop on all cellphone transmissions in the area without fear of detection. The earliest U.S. cellular telephony systems relied on the high cost of cellular-capable receivers (or scanners) for security. When such scanners become affordable and widely available, the cellphone industry lobbied for protective legislation. But these legal prohibitions have failed to solve the problem, and systems architects have been forced to turn increasingly to cryptography for more robust security.
The cellular telephony industry players are especially concerned with fraud prevention. The FCC estimates that the cellular industry loses more than $400 million per year to fraud [FCC97]. Cellphone cloning is probably the foremost form of this problem. Because most of today's cellphones identify themselves over public radio links by sending their identity information in the clear, eavesdroppers can (and do) easily misappropriate others' identity information to make fraudulent phone calls. While the latest digital cellphones currently offer some weak protection against casual eavesdroppers because digital technology is so new that inexpensive digital scanners have not yet become widely available, the president of the Cellular Telecommunications Industry Association testified in recent Congressional hearings [Whe97] that ``history will likely repeat itself as digital scanners and decoders, though expensive now, drop in price in the future.''
Cryptographic mechanisms are one obvious way to combat cloning fraud, and indeed, the industry is turning to cryptography for protection. In 1992, the TR-45 working group within the Telecommunications Industry Association (TIA) developed a standard for integration of cryptographic technology into tomorrow's digital cellular systems [TIA92], which has been updated at least once [TIA95]. Some of the most recent cellphones to hit the market already include these cryptographic protection mechanisms [Nok96].
The TIA standard [TIA95] describes four cryptographic primitives for use in North American digital cellular systems:
 .
.Note that CMEA is not used to protect voice communications. Instead, it is intended to protect sensitive control data, such as the digits dialed by the cellphone user. A successful break of CMEA might reveal user calling patterns. Also sent CMEA-encrypted are digits dialed (all DTMF tones) by the remote endpoint and alphanumeric personal pages recieved by the cellphone user. Finally, compromise of the control channel contents could lead to any confidential data the user types on the keypad: calling card PIN numbers may be an especially widespread concern, and credit card numbers, bank account numbers, and voicemail PIN numbers are also at risk.
This paper is organized as follows. We describe CMEA in Section 2 for reference. Next, Section 3 lists some observations that form a foundation for our later analysis. Then we give effective chosen- and known-plaintext attacks on CMEA in Sections 4 and 5. Finally, Section 6 concludes.
We describe the CMEA specification fully here for reference. CMEA is a byte-oriented variable-width block cipher with a 64 bit key. Block sizes may be any number of bytes; in practice, US cellular telephony systems typically apply CMEA to 2-6 byte blocks, with the block size potentially varying without any key changes. CMEA is quite simple, and appears to be optimized for 8-bit microprocessors with severe resource limitations.
CMEA consists of three layers. The first layer performs one non-linear pass on the block; this effects left-to-right diffusion. The second layer is a purely linear, unkeyed operation intended to make changes propagate in the opposite direction. One can think of the second step as (roughly speaking) XORing the right half of the block onto the left half. The third layer performs a final non-linear pass on the block from left to right; in fact, it is the inverse of the first layer.
CMEA obtains the non-linearity in the first and third layer from a 8-bit keyed lookup table known as the T-box. The T-box calculates its 8-bit output as
![]()
given input byte x and 8-byte key ![]() .
In this equation C is an unkeyed 8-bit lookup table known as the CaveTable;
all operations are performed using 8-bit arithmetic.
The CaveTable is given in Figure 1,
.
In this equation C is an unkeyed 8-bit lookup table known as the CaveTable;
all operations are performed using 8-bit arithmetic.
The CaveTable is given in Figure 1,
We now provide a specification of CMEA.
The algorithm encrypts a n-byte message ![]() to a ciphertext
to a ciphertext ![]() under the key
under the key ![]() as follows:
as follows:
Here all operations are byte-wide arithmetic: + and - are addition and subtraction modulo 256,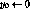
for

¯
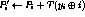

for
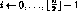
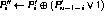
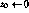
for
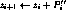

CMEA is specified in [TIA92, TIA95]; it is also described in U.S. Patent 5,159,634 [Ree91], though a different T-box method is listed.
First, we list some preliminary observations:
J. Hillyard [Hil97] has noted that codebook attacks may still be possible in practice. In some contexts, each digit dialed will be encrypted in a separate CMEA block (with fixed padding); because CMEA is used in ECB mode, the result is a simple substitution cipher on the digits 0-9. Techniques from classical cryptography may well suffice to recover useful information about the dialed digits, especially when side information is available.
The skew in the CaveTable means that the T-box values are skewed, too: we know T(i)-i must appear in the CaveTable, so for any input to the T-box, we can immediately rule out 92 possibilities for the corresponding T-box output without needing any knowledge of the CMEA key.
CMEA is weak against chosen-plaintext attacks:
one can recover all of the T-box entries with about 338 chosen texts
(on average) and very little work.
This attack works on any fixed block length n;SPMgt;2; the attacker
is not assumed to have control over n.
We have implemented the attack to empirically verify it for correctness;
the attack is extremely successful in our tests.
The attack proceeds in two stages, first recovering T(0),
and then recovering the remainder of the T-box entries;
the CMEA key itself is never identified.
First, one learns T(0) with (256-92)/2=82 chosen plaintexts (on average).
For each guess x at the value of T(0), obtain the
encryption of the message ![]() ,
e.g. the message P where each byte has the value 1-x;
if the result is of the form
,
e.g. the message P where each byte has the value 1-x;
if the result is of the form ![]() then we can conclude with high probability that indeed T(0)=x.
False alarms occasionally occur, but they can be ruled out quickly in
the second phase because of the skewed CaveTable distribution.
Note that there are only 256-92=164 possible values of T(0),
since T(0) must appear in the CaveTable, and therefore we expect
to identify the correct value after about 164/2=82 trials, on average.
then we can conclude with high probability that indeed T(0)=x.
False alarms occasionally occur, but they can be ruled out quickly in
the second phase because of the skewed CaveTable distribution.
Note that there are only 256-92=164 possible values of T(0),
since T(0) must appear in the CaveTable, and therefore we expect
to identify the correct value after about 164/2=82 trials, on average.
In the second phase of the attack,
one learns all of the remaining T-box entries with
256 more chosen plaintexts.
For each byte j, to learn the value of T(j), let
![]() , where the desired blocks are n
bytes long. Obtain the encryption of the message
, where the desired blocks are n
bytes long. Obtain the encryption of the message
![]() ;
if the result is of the form
;
if the result is of the form ![]() , then we may conclude
that T(j) = t, except for a possible error in the LSB.
A more sophisticated analysis can resolve the uncertainty in
the LSB of the T-box entries.
, then we may conclude
that T(j) = t, except for a possible error in the LSB.
A more sophisticated analysis can resolve the uncertainty in
the LSB of the T-box entries.
In practice, chosen-plaintext queries may be available in some special situations. Suppose the targeted cellphone user can be persuaded to a call a phone number under the attacker's control--perhaps a menuized survey, answering machine, or operator. The phone message the user receives might prompt the user to enter digits (chosen in advance by the attacker), thus silently enabling a chosen-plaintext attack on CMEA. Alternatively, the phone message might send chosen DTMF tones to the targetted cellphone user, thus mounting chosen-plaintext queries at will.
We now describe a known plaintext attack on CMEA needing about 40-80
known texts.
The attack assumes that each known plaintext is enciphered
with a 3-byte block width.
Our (unoptimized) implementation has a time
complexity of ![]() to
to ![]() , and can be easily parallelized.
, and can be easily parallelized.
Our cryptanalysis has two phases. The first phase
gathers information about the T-box entries from the known
CMEA encryptions, eliminating many possibilities for the values of each
T-box output. In this way we reduce the problem to that of
cryptanalysis of the T-box algorithm, given some partial information
about T-box input/output pairs. In the second phase, we take advantage
of the statistical biases in the CaveTable to cryptanalyze the T-box and
recover the CMEA key ![]() , using pruned search and
meet-in-the-middle techniques to enhance performance.
, using pruned search and
meet-in-the-middle techniques to enhance performance.
The first phase is implemented as follows.
Because T(0) occupies a position of special importance,
we exhaustively search over the 164 possibilities for T(0).
(Remember that T(0) must appear in the CaveTable, and so there
are only 256-92=164 possibilities for it.)
For each guess at T(0),
we set up a ![]() array
array ![]() which records for each i,j whether T(i)=j is possible.
All values for T(i), i;SPMgt;0 are initially listed as possible.
Since T(i)-i is a CaveTable output
and the CaveTable has an uneven distribution,
we can immediately rule out 92 values for T(i).
which records for each i,j whether T(i)=j is possible.
All values for T(i), i;SPMgt;0 are initially listed as possible.
Since T(i)-i is a CaveTable output
and the CaveTable has an uneven distribution,
we can immediately rule out 92 values for T(i).
Next, we gradually eliminate impossible values using the known texts as follows. The general idea is that each known plaintext/ciphertext pair lets us establish several implications of the form
If we have already eliminated T(i')=j' as impossible,
then we can conclude that T(i)=j is also impossible
via the contrapositive of (1).
In this way, we successively rule out more and more possibilities
in the ![]() array, until we either reach a contradiction
(in which case we start over with another guess at T(0))
or until we run out of logical deductions to make
(in which case we proceed to the second phase).
array, until we either reach a contradiction
(in which case we start over with another guess at T(0))
or until we run out of logical deductions to make
(in which case we proceed to the second phase).
The second phase recovers the CMEA key from the information about T
previously accumulated in the ![]() array.
Our simplest key recovery algorithm is based on pruned search.
First, one guesses
array.
Our simplest key recovery algorithm is based on pruned search.
First, one guesses ![]() and
and ![]() .
Then, we peel off the effect of the last 1/4 of the T-box,
and check whether the intermediate value is a possible CaveTable output.
The intermediate value must always be one of the 164 possible
CaveTable outputs when we find the correct
.
Then, we peel off the effect of the last 1/4 of the T-box,
and check whether the intermediate value is a possible CaveTable output.
The intermediate value must always be one of the 164 possible
CaveTable outputs when we find the correct ![]() ;
because the CaveTable is so heavily skewed,
incorrect
;
because the CaveTable is so heavily skewed,
incorrect ![]() guesses will usually be quickly identified by
this test, if we have knowledge about a number of T-box entries.
Next, one continues by guessing
guesses will usually be quickly identified by
this test, if we have knowledge about a number of T-box entries.
Next, one continues by guessing ![]() , pruning the search
as before, and continuing the pruned search until the entire key
is recovered.
This technique is very effective if enough information is available
in the
, pruning the search
as before, and continuing the pruned search until the entire key
is recovered.
This technique is very effective if enough information is available
in the ![]() array.
array.
Unfortunately, pruned search very quickly becomes extremely
computationally intensive if too few known texts are available:
at each stage, too many candidates survive the pruning, and
the search complexity grows exponentially.
We have a more sophisticated key recovery algorithm which can reduce
the computation workload dramatically in these instances.
The basic idea is that the T-box is subject to a classic
meet-in-the-middle optimization:
one can work halfway through the T-box given only ![]() ,
and one can work backwards up to the middle given just
,
and one can work backwards up to the middle given just ![]() .
This enables us to precompute a lookup table that contains the
intermediate value corresponding to each
.
This enables us to precompute a lookup table that contains the
intermediate value corresponding to each ![]() value.
Then, we try each possible
value.
Then, we try each possible ![]() value, work backwards
through some known T-box outputs, and look for a match in
the precomputed lookup table.
Of course the search pruning techniques can be applied to
value, work backwards
through some known T-box outputs, and look for a match in
the precomputed lookup table.
Of course the search pruning techniques can be applied to
![]() to further reduce the complexity of the
meet-in-the-middle algorithm.
The combination of pruned search and meet-in-the-middle cryptanalysis
allows us to efficiently recover the entire CMEA key
with as few as 40-80 known plaintexts.
to further reduce the complexity of the
meet-in-the-middle algorithm.
The combination of pruned search and meet-in-the-middle cryptanalysis
allows us to efficiently recover the entire CMEA key
with as few as 40-80 known plaintexts.
We describe how to derive implications of the form (1)
from some known CMEA encryptions for the first phase.
Knowing T(0) lets us recover (for each plaintext/ciphertext pair P,C)
![]() and thus we learn the inputs to the two T-boxes
lookups used to modify
and thus we learn the inputs to the two T-boxes
lookups used to modify ![]() .
We make a guess (e.g. T(i)=j)
about the output of the first aforementioned T-box lookup.
We can derive the (implied) output of the second T-box lookup
by using the known text pair.
Then we deduce the (implied) values of
.
We make a guess (e.g. T(i)=j)
about the output of the first aforementioned T-box lookup.
We can derive the (implied) output of the second T-box lookup
by using the known text pair.
Then we deduce the (implied) values of ![]() and
thus the inputs to the two T-box lookups used to modify
and
thus the inputs to the two T-box lookups used to modify ![]() .
Next we derive the quantity XORed into
.
Next we derive the quantity XORed into ![]() in the second
CMEA layer, which lets us calculate the (implied) outputs of the
two T-box lookups that modify
in the second
CMEA layer, which lets us calculate the (implied) outputs of the
two T-box lookups that modify ![]() .
Therefore our assumption T(i)=j implies
three other derived equations of the form T(i')=j';
if any of those three derived input/output pairs i',j' is listed as
impossible in
.
Therefore our assumption T(i)=j implies
three other derived equations of the form T(i')=j';
if any of those three derived input/output pairs i',j' is listed as
impossible in ![]() , then we have
found a contradiction, and we may conclude that our original
assumption was wrong--namely, that the assumed value of
the T-box entry was in fact impossible, and that value may
be marked as impossible in
, then we have
found a contradiction, and we may conclude that our original
assumption was wrong--namely, that the assumed value of
the T-box entry was in fact impossible, and that value may
be marked as impossible in ![]() .
.
In this way, we can gradually rule out many entries ![]() as impossible.
We loop over all i,j and all known texts, until no more deductions
can be made.
If our guess at T(0) was incorrect, then there will probably
be a T-box input for which no possible output values remain,
and in this case we will be able to discard our incorrect guess at T(0).
Otherwise, we tentatively conclude that our guess at T(0) was
correct, and we can usually identify several other known T-box
input/output pairs;
with this information in hand, we proceed to the second phase.
Typically the first phase will identify T(0) uniquely when sufficiently
many known plaintexts (about 50 or more) are available;
if more possibilities for T(0) are found,
the second phase will be invoked for such possibility.
as impossible.
We loop over all i,j and all known texts, until no more deductions
can be made.
If our guess at T(0) was incorrect, then there will probably
be a T-box input for which no possible output values remain,
and in this case we will be able to discard our incorrect guess at T(0).
Otherwise, we tentatively conclude that our guess at T(0) was
correct, and we can usually identify several other known T-box
input/output pairs;
with this information in hand, we proceed to the second phase.
Typically the first phase will identify T(0) uniquely when sufficiently
many known plaintexts (about 50 or more) are available;
if more possibilities for T(0) are found,
the second phase will be invoked for such possibility.
First, we describe how to prune key trials during the key recovery search. Note that a T-box output is of the form
![]()
for some unknown CaveTable output O.
We can calculate ![]() for all CaveTable
outputs and check whether each such j is listed as possible in
for all CaveTable
outputs and check whether each such j is listed as possible in ![]() ;
if every such j is listed as impossible,
then we can recognize our guess at
;
if every such j is listed as impossible,
then we can recognize our guess at ![]() as incorrect.
Because there are only 164 possible CaveTable outputs,
incorrect guesses at
as incorrect.
Because there are only 164 possible CaveTable outputs,
incorrect guesses at ![]() will usually be ruled out
by some i as long as there is enough information in the
will usually be ruled out
by some i as long as there is enough information in the ![]() array.
These incorrect guesses at
array.
These incorrect guesses at ![]() can thus be
pruned from the search tree without any further work.
can thus be
pruned from the search tree without any further work.
Next, we give some more details on the meet-in-the-middle approach.
This approach is only applicable when we have enough known plaintexts
to identify 4 known T-box input/output values
(a,T(a)),(b,T(b)),(c,T(c)),(d,T(d))
from the ![]() array.
For each
array.
For each ![]() , we compute the intermediate values a',b',c',d'
formed after computing T through the known key bytes;
for example,
, we compute the intermediate values a',b',c',d'
formed after computing T through the known key bytes;
for example, ![]() .
Next we form the 24-bit index n = (a'-d',b'-d',c'-d'),
and insert the pair
.
Next we form the 24-bit index n = (a'-d',b'-d',c'-d'),
and insert the pair ![]() into a large hash
table keyed on n.
After repeating for all
into a large hash
table keyed on n.
After repeating for all ![]() possible
possible ![]() values,
we have built a precomputed lookup table suitable for use in the
meet-in-the-middle optimization.
To check a trial
values,
we have built a precomputed lookup table suitable for use in the
meet-in-the-middle optimization.
To check a trial ![]() value, we work backwards from
T(a),T(b),T(c),T(d) as far possible given only
value, we work backwards from
T(a),T(b),T(c),T(d) as far possible given only ![]() and identify the intermediate values a'',b'',c'',d''.
The intermediate values
reflect the values of the T-box computations just after addition
of
and identify the intermediate values a'',b'',c'',d''.
The intermediate values
reflect the values of the T-box computations just after addition
of ![]() : for example,
: for example,
![]()
We see that a'' can be identified from a,T(a) by working
backwards through the T-box computation and inverting the CaveTable
where necessary,
and b'',c'',d'' can be found similarly.
Then we form the 24-bit index m = (a''-d'',b''-d'',c''-d''),
search in the precomputed hash table for a matching entry
![]() with n=m, and use trial encryption to check
the resulting
with n=m, and use trial encryption to check
the resulting ![]() value.
Note that if our guess at
value.
Note that if our guess at ![]() was correct, we have
was correct, we have
![]() etc., so that the correct value of
etc., so that the correct value of ![]() will show up in our search of the precomputed hash table and the
correct value of
will show up in our search of the precomputed hash table and the
correct value of ![]() can be derived as a''-a';
this ensures that we will identify
can be derived as a''-a';
this ensures that we will identify ![]() correctly.
correctly.
Pruned search lets us dramatically reduce the number of key candidates
tried, if there is enough information in the ![]() array.
The meet-in-the-middle optimization is a time-space tradeoff that
further reduces the computational workload when 4 known T-box
input/output values are available.
Combining the two approaches yields a key recovery algorithm for
the second phase that is very efficient on a standard 100 MHz Pentium
with 40 Mb of memory.
Furthermore, the search algorithm can easily be parallelized for
even greater performance if necessary.
Note that we make heavy use of the non-uniform output distribution
of the CaveTable, and these analysis techniques would not work
if the CaveTable were unbiased.
array.
The meet-in-the-middle optimization is a time-space tradeoff that
further reduces the computational workload when 4 known T-box
input/output values are available.
Combining the two approaches yields a key recovery algorithm for
the second phase that is very efficient on a standard 100 MHz Pentium
with 40 Mb of memory.
Furthermore, the search algorithm can easily be parallelized for
even greater performance if necessary.
Note that we make heavy use of the non-uniform output distribution
of the CaveTable, and these analysis techniques would not work
if the CaveTable were unbiased.
This known plaintext attack is much more devastating than the chosen plaintext attack described in Section 3.1. Chosen plaintext may be difficult to obtain in practice, but known plaintext is likely to be much easier to acquire.
There are a number of realistic ways that the required known plaintext can be collected in practice. Dialed digits are typically CMEA-encrypted with 3-byte blocks; typically each block will contain only one digit, and often the telephone number dialed will be known. DTMF tones sent on the line will usually be CMEA-encrypted. If the user can be persuaded to dial a number under adversarial control, using their calling card, then the DTMF tones and user-dialed digits will be known to the attacker, providing a ready source of known plaintext; after recovering the CMEA key in a known-plaintext attack, the attacker could decrypt the calling card number and make false calls billed to the victim's name. Furthermore, alphanumeric pages sent to cellular phones are becoming increasingly common, and alphanumeric pages are sent over the control channel. These pages may have a large known component, which will provide some known plaintext. It should be clear that known plaintext may be available from a number of potential sources.
In this section, we have discussed cryptanalysis of CMEA with 3-byte
block widths.
A block width of 3 bytes is a natural choice to examine.
Known plaintext with 3-byte block widths
is often readily available in practice;
for instance, dialed digits are typically
encrypted and transmitted using 3-byte block widths in nearly all digital
cellular architectures.
Moreover, CMEA appears to be easiest to analyze for short block widths,
and most cellular standards avoid block widths shorter
than 3 bytes.
Therefore, 3-byte blocks are a good indicator of the strength of CMEA
as used in phone systems; by giving a known-plaintext
attack on CMEA with 3-byte blocks,
we show that the control channel is not protected adequately in nearly
all of the North American digital cellular phone systems.
We saw above that CMEA is insecure when used with a 3-byte block width; now we show that the situation is even worse for 2-byte blocks. In this section, we present an attack on CMEA needing just 4 known plaintexts when 2-byte blocks are in use. Most cellular standards avoid using CMEA with 2-byte blocks. However, this is not just a theoretical attack: a few cellular systems, such as IS-95 (CDMA), do apply CMEA with a 2-byte block width to protect dialed digits, and they will be vulnerable to the improved attack.
The known-plaintext attack on 2-byte blocks
follows immediately from our earlier discussion.
First, we guess T(0);
that lets us recover 4 more T-box values from the first two known texts.
(There is no need for a stage corresponding to the first phase of
the attack on 3-byte blocks, as we can trivially derive 4 known input/output
pairs for the T-box from the known texts.)
With those known T-box input/output pairs,
we perform a pruned meet-in-the-middle search
to derive a number of possibilities for the full CMEA key,
as described in Section 4.2.
The correct CMEA key can be quickly recognized by trial decryption.
The pruned meet-in-the-middle search has work factor
![]() -
- ![]() , and we will need to do about 30 iterations
of the search to handle each of the possibilities for T(0).
In sum, this attack requires just 4 known 2-byte plaintexts
and has time complexity about
, and we will need to do about 30 iterations
of the search to handle each of the possibilities for T(0).
In sum, this attack requires just 4 known 2-byte plaintexts
and has time complexity about ![]() -
-  .
.
In fact, the plaintext requirements can be reduced even further, to just two known 2-byte plaintexts and some extra ciphertexts. We don't need to know the decryption of the extra ciphertexts: the extra ciphertexts must merely be enough to information-theoretically determine the CMEA key, so that all incorrect key trials can be recognized and discarded. Note the plaintext often contains redundancy--for instance, when it contains dialed digits, there are only 10 possible values for each nibble, and often much of the input is a public fixed value--so in practice obtaining the necessary extra ciphertexts should be very easy.
We have presented several attacks on CMEA, and some of them may be realistically exploitable in practice. We described several possible ways to obtain known plaintext information. One attack that applies to nearly all North American digital cellular standards needs about 40-80 known plaintexts; that many known texts may be available in some situations, although availability is likely to depend on subtleties of the cellular phone system implementation. Though it does not apply to most digital cellphone standards, another attack needs just 4 known plaintexts, which is a much more realistic assumption. At a minimum, these attacks illuminate fundamental certificational weaknesses in CMEA. At worst, widespread attacks on CMEA might be possible in practice.
Our cryptanalysis of CMEA underscores the need for an open cryptographic review process. Betting on new algorithms is always dangerous, and closed-door design and proprietary standards are not conducive to the best odds.
Since being exposed to public scrutiny, three of the four proprietary TIA cryptographic algorithms have been broken: the voice privacy protection was shown to be insecure as early as 1992 [Bar92, CFP93], this paper cryptanalyzes CMEA, and ORYX was recently broken by the authors [WSK97]. This poor success rate provides a strong argument against closed-door design.
In addition, our analysis also shows the importance of explicitly stating security assumptions during every step of the design and development process, and of not reusing security components without throroughly examining the implications of reuse. The CaveTable was designed to have the security properties CAVE needed. Designers reused it for CMEA because they were low on space; this turned out to be a bad idea. CMEA requires different properties from the CaveTable than CAVE does.
In short, CMEA is deeply flawed, and should be carefully reconsidered.
Greg Rose first pointed out the insecurity of CMEA, and he deserves the credit for that discovery. We were not aware of serious flaws in CMEA until we heard over the grapevine that he had found an effective known-plaintext attack on CMEA; this tip provided the motivation to look more closely at CMEA until we managed to independently re-derive the attack described in this paper. Unfortunately he is not free to publish his analysis, so we offer ours instead. We are extremely grateful to Greg Rose for his immeasurable help.
Also, we thank an anonymous party (for scanning the cellphone cryptography standard and posting it to the Internet [TIA92]), John Young (for acting as a clearinghouse for resources on cellphone crypto), Ron Rivest (for many helpful comments on the presentation of our results), Steve Schear (for some assistance navigating the maze of cellular standards), Niels Ferguson (for useful feedback), and all those early readers who independently pointed out that the number of possibilities for T(0) could be reduced from 256 to 164 in the known plaintext attack.
Cryptanalysis of the Cellular Message Encryption Algorithm
This document was generated using the LaTeX2HTML translator Version 96.1 (Feb 5, 1996) Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html paper10.tex.
The translation was initiated by David Wagner on Fri May 30 15:57:40 PDT 1997
